什么是深度优先搜索?
深度优先搜索(DFS)是与广度优先搜索想对应的算法,它的思想是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底,这种尽量往深处走的概念即是深度优先的概念。
深度优先搜索适用于哪些场景?
深度优先搜索算法适用场景是在数组、图、树…等数据结构中,查询符合条件的解,虽是比较暴力的搜索算法,但因为只求有解,所以消耗比较小,深度优先搜索算法是联合回溯的算法思想,可以使用递归来实现,
场景1 二叉树
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
function searchBST(root: TreeNode | null, val: number): TreeNode | null {
let searchedNode: TreeNode | null = null;
let dfs = function (node: TreeNode | null) {
if (node === null||searchedNode) {
return;
}
console.log(node.val);
if(node.val === val){
searchedNode = node;
return;
}
dfs(node.left);
dfs(node.right);
}
dfs(root);
return searchedNode;
}
|
以上就是一个最简洁的深度优先搜索的样本,给定二叉搜索树(BST)的根节点和一个值,需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
假设树为下图,需要查找的目标值为7
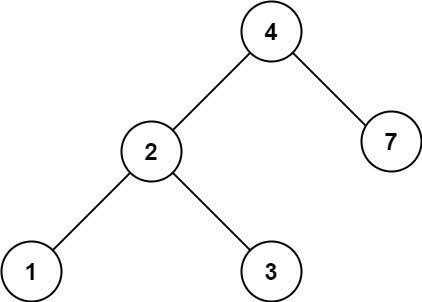
那么输出值的顺序应该是深度优先,如4、2、1、3,7,弹出
场景2
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。
示例:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| function combine(n: number, k: number): number[][] {
const ans: number[][] = [];
const temp: number[] = [];
const dfs = (cur: number,n: number,k: number) => {
if(temp.length === k){
ans.push([...temp]);
return;
}
if(cur === n + 1){
return;
}
temp.push(cur);
dfs(cur + 1,n,k);
temp.pop();
dfs(cur + 1,n,k);
}
dfs(1,n,k);
return ans;
}
|
场景3
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。 叶子节点 是指没有子节点的节点。
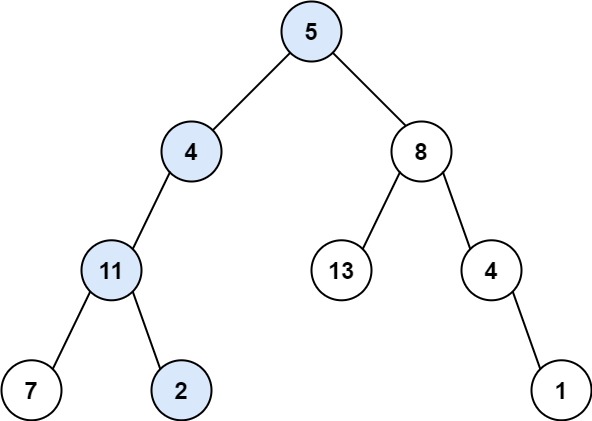
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
function hasPathSum(root: TreeNode | null, targetSum: number): boolean {
let result: boolean = false;
let isEnd: boolean = false;
if (!root) {
return false;
}
if (root.val === targetSum) {
if (!root.left && !root.right) {
return true;
}
}
const dfs = (node: TreeNode | null, sum: number, prevSum: number) => {
if (!node) {
sum = prevSum;
return;
}
if (isEnd) {
return;
}
if (sum === targetSum) {
if (!node.left && !node.right) {
result = true;
isEnd = true;
return;
}
}
dfs(node.left, sum + (node.left?.val ?? 0), sum);
dfs(node.right, sum + (node.right?.val ?? 0), sum);
}
dfs(root, root.val, 0);
return result;
};
|
关于此算法的心得
深度优先搜索是一个算法思想,在方法体中注意三个边界条件
- 被搜索的对象集合已经用完-弹出栈,
- 已经完成目标-弹出栈
- 满足搜索条件,声明已经完成目标,弹出栈
在进行递归栈的时候,应以深度进行优先,往深处将递归语句进行入栈,如果没有搜索到,再进行回溯,然后进行深度搜索